

A análise de dados se tornou essencial em uma era movida por decisões informadas e insights valiosos. Nesse sentido, para atender a essa demanda crescente, ferramentas robustas como o PySpark emergem como aliados indispensáveis. Além disso, essa poderosa biblioteca, construída sobre o Apache Spark, oferece capacidades excepcionais para processar e analisar grandes volumes de dados com eficiência e escalabilidade. Portanto, compreender suas funcionalidades é fundamental para profissionais que buscam se destacar no campo da análise de dados. Neste artigo, exploraremos como o PySpark pode transformar a forma como lidamos com dados, bem como discutiremos seus principais benefícios e aplicações. Por fim, entender o papel do PySpark é essencial para organizações que desejam se manter competitivas no mercado atual.
O Que é PySpark e Por Que Ele é Importante?
O PySpark é a interface Python para o Apache Spark, um framework de computação distribuída que facilita o processamento de grandes conjuntos de dados em clusters de computadores. Enquanto outras ferramentas de análise podem se limitar a máquinas individuais, o PySpark permite escalar análises para milhares de máquinas, garantindo velocidade e confiabilidade.
Com a explosão do big data, empresas enfrentam desafios significativos ao tentar processar e entender os dados coletados. É aqui que a interface brilha. Ele combina a simplicidade do Python com o poder do Spark, proporcionando uma plataforma flexível para resolver problemas complexos. Por exemplo, ele pode lidar com tarefas como extração, transformação e carregamento (ETL), modelagem de dados e aprendizado de máquina de forma eficiente.
Vantagens
1. Escalabilidade
Uma das maiores vantagens do PySpark é sua capacidade de escalabilidade. Por exemplo, ele permite que tarefas sejam divididas em várias máquinas, otimizando o uso de recursos e reduzindo o tempo de execução. Além disso, essa característica o torna ideal para lidar com datasets massivos, especialmente em casos onde soluções tradicionais falhariam ou levariam dias para produzir resultados. Portanto, ao escolher o PySpark, as empresas podem enfrentar desafios de big data com eficiência e rapidez.
2. Processamento Rápido
O PySpark utiliza a memória RAM de maneira eficiente para realizar cálculos paralelos, o que acelera consideravelmente o processamento. Diferentemente de abordagens tradicionais que dependem do acesso frequente ao disco, ele mantém os dados na memória sempre que possível, garantindo resultados mais rápidos.
3. Flexibilidade
Com suporte para APIs em Python, Java, Scala e R, o Apache Spark se torna acessível para profissionais com diferentes níveis de experiência e preferências de linguagem. Além disso, no PySpark, os desenvolvedores podem aproveitar a simplicidade e a riqueza de bibliotecas Python para tarefas complementares, como visualização de dados e aprendizado de máquina. Dessa forma, a integração entre o PySpark e o ecossistema Python proporciona uma experiência robusta e eficiente, especialmente para aqueles que já estão familiarizados com a linguagem.
4. Integração com o Ecosistema Big Data
O PySpark se integra facilmente a outros componentes do ecossistema big data, como Hadoop, Hive e Kafka. Essa compatibilidade o torna uma escolha natural para arquiteturas modernas de dados. Além disso, ele pode se conectar diretamente a bancos de dados relacionais, sistemas de armazenamento na nuvem e APIs, facilitando o fluxo de trabalho.
5. Ferramentas de Machine Learning
A biblioteca MLlib do Spark traz recursos de aprendizado de máquina para o PySpark, permitindo a criação de modelos preditivos escaláveis. Desde regressão e classificação até clustering e sistemas de recomendação, a MLlib oferece soluções prontas para uso, agilizando o desenvolvimento de projetos complexos.
Casos de Uso Reais
O PySpark não é apenas uma ferramenta teórica; ele está no centro de inúmeras aplicações práticas. Vamos explorar algumas situações em que ele demonstra seu verdadeiro potencial.
Análise de Dados em Tempo Real
Empresas que trabalham com dados em tempo real, como plataformas de streaming ou serviços de transporte, se beneficiam do PySpark para processar eventos instantaneamente. Ele pode monitorar transações financeiras, prever congestionamentos de tráfego ou ajustar recomendações de conteúdo com base em comportamento do usuário.
ETL em Big Data
Muitas organizações utilizam o PySpark para pipelines ETL em grande escala. Por exemplo, dados brutos coletados de dispositivos IoT ou logs de servidores podem ser limpos, transformados e armazenados em sistemas analíticos para posteriores análises.
Aprendizado de Máquina
Empresas que desenvolvem modelos preditivos frequentemente escolhem o PySpark para criar pipelines de aprendizado de máquina. Sua capacidade de lidar com grandes volumes de dados permite que modelos sejam treinados em menos tempo e com maior precisão.
Análise de Sentimentos
Para organizações que desejam entender a percepção do público, como marcas ou instituições políticas, o PySpark pode ser usado para processar grandes volumes de textos de redes sociais, classificando sentimentos e identificando tendências.
Principais Componentes do PySpark
Para aproveitar ao máximo o PySpark, é importante entender seus principais componentes:
- RDD (Resilient Distributed Dataset): A estrutura fundamental de dados no PySpark. Permite manipulação distribuída e tolerância a falhas.
- DataFrame: Uma abstração de dados tabulares semelhante ao Pandas, mas otimizada para execução distribuída.
- SQL: Integração com consultas SQL para facilitar a análise de dados estruturados.
- Streaming: Para processamento de fluxos de dados em tempo real.
- MLlib: Biblioteca de aprendizado de máquina para construção de modelos preditivos escaláveis.
Como Começar com o PySpark
Configuração Inicial
Antes de usar o PySpark, é necessário configurar seu ambiente. Primeiro, instale o Apache Spark e o Java Development Kit (JDK). Depois, utilize gerenciadores de pacotes Python, como pip, para instalar o PySpark:

Primeiros Passos no Código
Um exemplo básico de código com PySpark é criar um DataFrame e realizar operações simples:
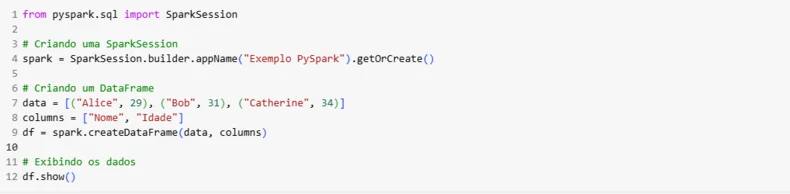
Esse pequeno exemplo ilustra como o PySpark facilita a manipulação de dados mesmo para iniciantes.
Melhores Práticas para Utilizar
- Otimização de Jobs: Utilize particionamento adequado para distribuir tarefas de forma equilibrada.
- Cache e Persistência: Cache os RDDs ou DataFrames frequentemente usados para evitar recomputações dispendiosas.
- Monitoramento: Use ferramentas como Spark UI para identificar gargalos e ajustar configurações.
- Integração com Ferramentas: Combine o PySpark com bibliotecas Python como Pandas, Matplotlib ou Scikit-learn para criar workflows completos.
O Futuro
Com o crescimento exponencial dos dados e a necessidade de análises rápidas, o PySpark deve continuar sendo uma das ferramentas mais relevantes no campo. Além disso, sua comunidade ativa e as constantes melhorias tornam-no um investimento valioso para profissionais e organizações. Portanto, ao adotar esta interface, empresas podem maximizar o valor dos dados enquanto se beneficiam de uma tecnologia robusta e amplamente aceita. Por exemplo, a capacidade de processar grandes volumes de dados em tempo real permite decisões mais informadas e ágeis. Consequentemente, investir no PySpark é uma estratégia inteligente para se manter competitivo em um mercado cada vez mais orientado por dados.
Em um mundo onde as informações são ouro, ferramentas como o PySpark não são apenas um diferencial, mas uma necessidade. De análises complexas a previsões precisas, ele oferece um conjunto completo de soluções para navegar no oceano de dados do futuro.










